Models & Performance
TwoFiftyTwo exposes model selection directly in the Research interface and in each Analyst task. This page documents the available models and the evaluation results used to guide model selection for different research use cases.
Available models
Sonnet 4.6 (1M)
The default model. Sonnet 4.6 runs with a one-million-token context window, enabling it to ingest large volumes of research material — entire earnings call transcripts, lengthy credit agreements, or hundreds of broker research emails — in a single pass without truncation.
Best for: Most financial research tasks, including long-document analysis, multi-source synthesis, and structured report generation.
Opus (1M)
A more capable model for complex, multi-step research tasks. Opus runs with a one-million-token context window and excels at nuanced reasoning, long-chain analysis, and synthesising conflicting or ambiguous source material.
Best for: Complex cross-source analysis, tasks requiring deeper reasoning, and research where accuracy on ambiguous or conflicting evidence is a priority.
GPT 5.5 (272K)
OpenAI’s GPT 5.5, available with a 272,000-token context window. Offers an alternative reasoning profile for tasks where a second perspective on the same sources is useful.
Best for: Comparative analysis, situations where you want a non-Anthropic model’s interpretation, or workflows that already rely on GPT-family outputs.
Effort level
The Effort level in the prompt bar affects the depth of the research plan, not the underlying model. The default is High.
| Setting | Behaviour | Best for |
|---|---|---|
| Medium | Generates a simpler plan and responds faster. Fewer research steps, narrower source coverage. | Quick factual lookups, exploratory queries, or checking whether TwoFiftyTwo has relevant data before committing to a full run. |
| High (default) | Generates a detailed multi-step plan before writing. Broader source coverage and better-structured output at the cost of slightly longer processing time. | Most financial research tasks — earnings analysis, credit reviews, thematic deep-dives, and any output that will be shared or archived. |
| Max | Generates the most exhaustive research plan. Maximum source coverage and the most thorough synthesis, with the longest processing time. | High-stakes deliverables where completeness is critical — investment committee memos, regulatory filings, or deep cross-source analysis. |
Choosing an effort level
- Default to High. It strikes the right balance for most tasks — thorough enough for shareable output without the wait of Max.
- Use Medium for speed. During an internal discussion, a live meeting, or an initial data-availability check, Medium gives you a usable answer faster.
- Use Max when completeness is critical. Reserve it for deliverables where missing a source or a nuance has real consequences.
- Quality does not affect which model is used. All three settings run on whichever model is selected in the Model control. See Available models for guidance on model selection.
Evaluations
Note: Results below are from the V1 benchmark run. GPT 5.5 was not included in this run and will be added in a subsequent evaluation.
Task types
Three task types are evaluated:
- Retrieval — extracting a specific factual value from a data provider or email corpus.
- Synthesis — summarising or aggregating information across multiple emails or sources.
- Reasoning — drawing an inference or interpretation from provided data or context. Golden answers are written by a domain expert showing the expected logical flow for the specific market context.
Evaluation framework
Each response is scored across four dimensions and subject to a hallucination gate.
- Correctness — factual accuracy at the statement level.
- Source Attribution — whether claims cite the correct data provider.
- Completeness — whether all required elements from the golden answer are present in the response.
- Conciseness — the proportion of assertions in the response that directly contribute to answering the query.
- Hallucination gate — contradicted assertions are not scored; they fail the response outright.
Composite weights differ between retrieval/synthesis tasks and reasoning tasks — correctness and source attribution carry more weight for retrieval, while completeness is weighted higher for reasoning to reflect the importance of covering key premises and acknowledging uncertainty.
Results — V1 benchmark run
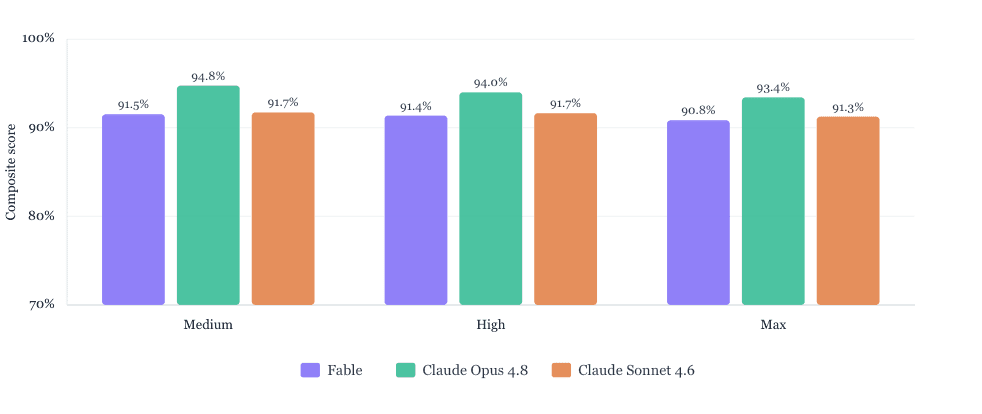
Claude Opus 4.8 leads across all three effort levels, with Claude Sonnet 4.6 and Fable closely grouped behind it. The spread between models is narrow, with all three models exceeding a 90% composite score — suggesting the choice of effort level has limited impact on absolute quality within this range.
Sonnet 4.6 is notably consistent: its composite score holds within 0.4 points across Medium, High, and Max. Opus shows a slightly larger drop at Max, which may reflect the more demanding research plans surfacing harder edge cases. Fable follows a similar pattern to Opus but scores lower overall.
For most tasks, Sonnet 4.6 at High offers the best balance of quality and speed. Opus is the better choice where the ceiling matters — complex reasoning tasks or high-stakes deliverables where the margin between 91% and 94% is meaningful.